GOTabPFN
GOTabPFN: From Feature Ordering to Compact Tokenization for Tabular Foundation Models on High-Dimensional Data introduces graph-guided feature ordering and compact tokenization for improving TabPFN-style tabular foundation models on high-dimensional tabular datasets.
1West Virginia University 2University of Utah
Overview
GOTabPFN targets high-dimensional tabular learning, especially HDLSS settings where the number of features can be much larger than the number of samples. The method learns a feature ordering using GO-LR, compresses local ordered feature neighborhoods with NSC-pSP, and passes compact meta-features to a frozen TabPFN-2.5 head.
Features are organized using graph structure and local refinement so nearby positions reflect useful dependencies.
Ordered neighborhoods are compressed into meta-features, reducing the burden of high-dimensional inputs.
The compact representation is passed to a frozen TabPFN-2.5 head for downstream prediction.
Architecture
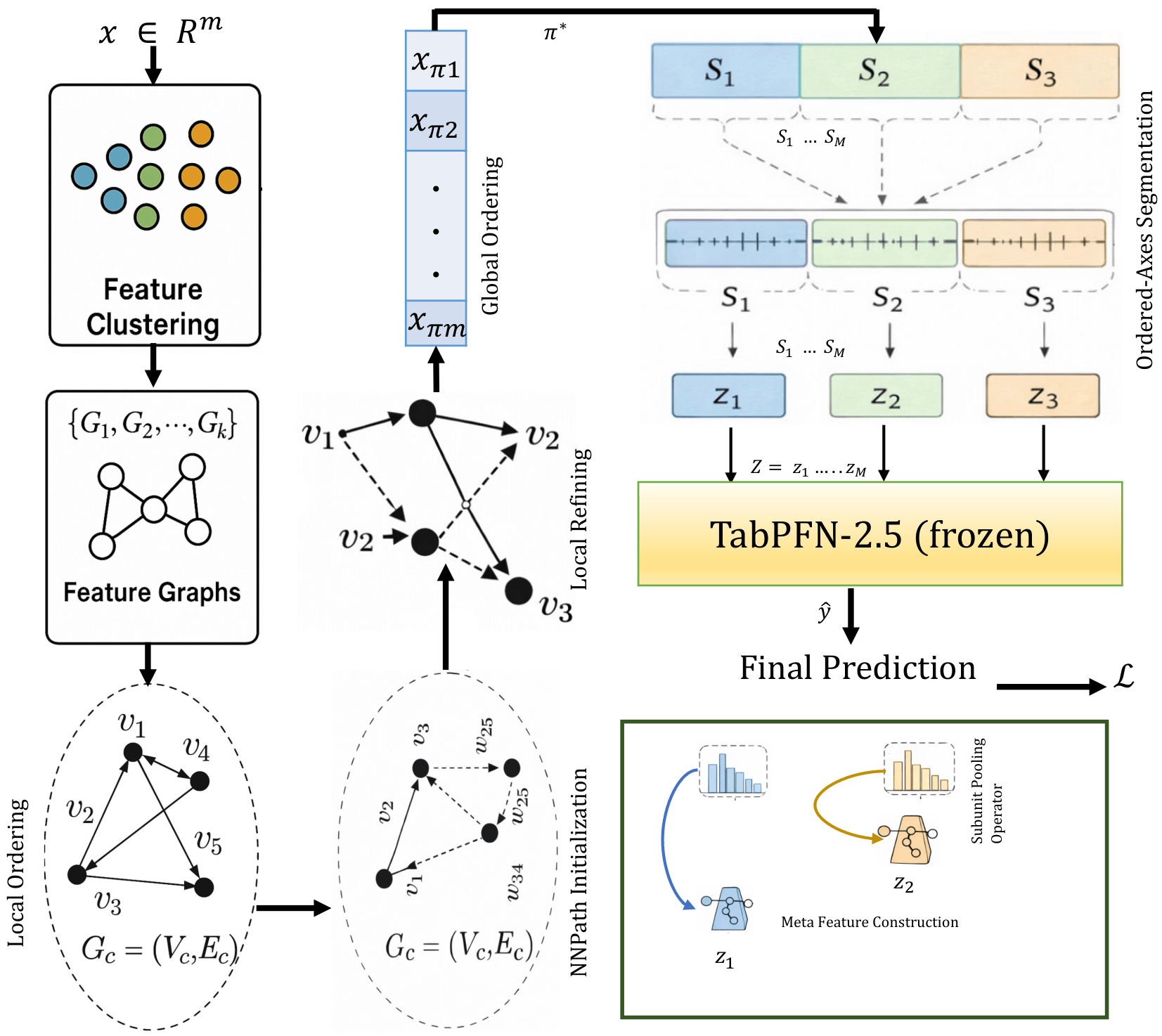
Method Components
- GO-LR: graph-guided feature ordering with local refinement.
- NSC-pSP: neighborhood/segment compression through PCA-IDF-aware principal subspace projection.
- Frozen TabPFN-2.5 head: downstream binary, multiclass, or regression prediction using compact meta-features.
- Diagnostics: dataset-level IDF/FOE/P-success, locality gains, LES, and AUC under the cumulative explained variance-IDF curve.
GO-LR: Graph-Guided Ordering with Local Refinement
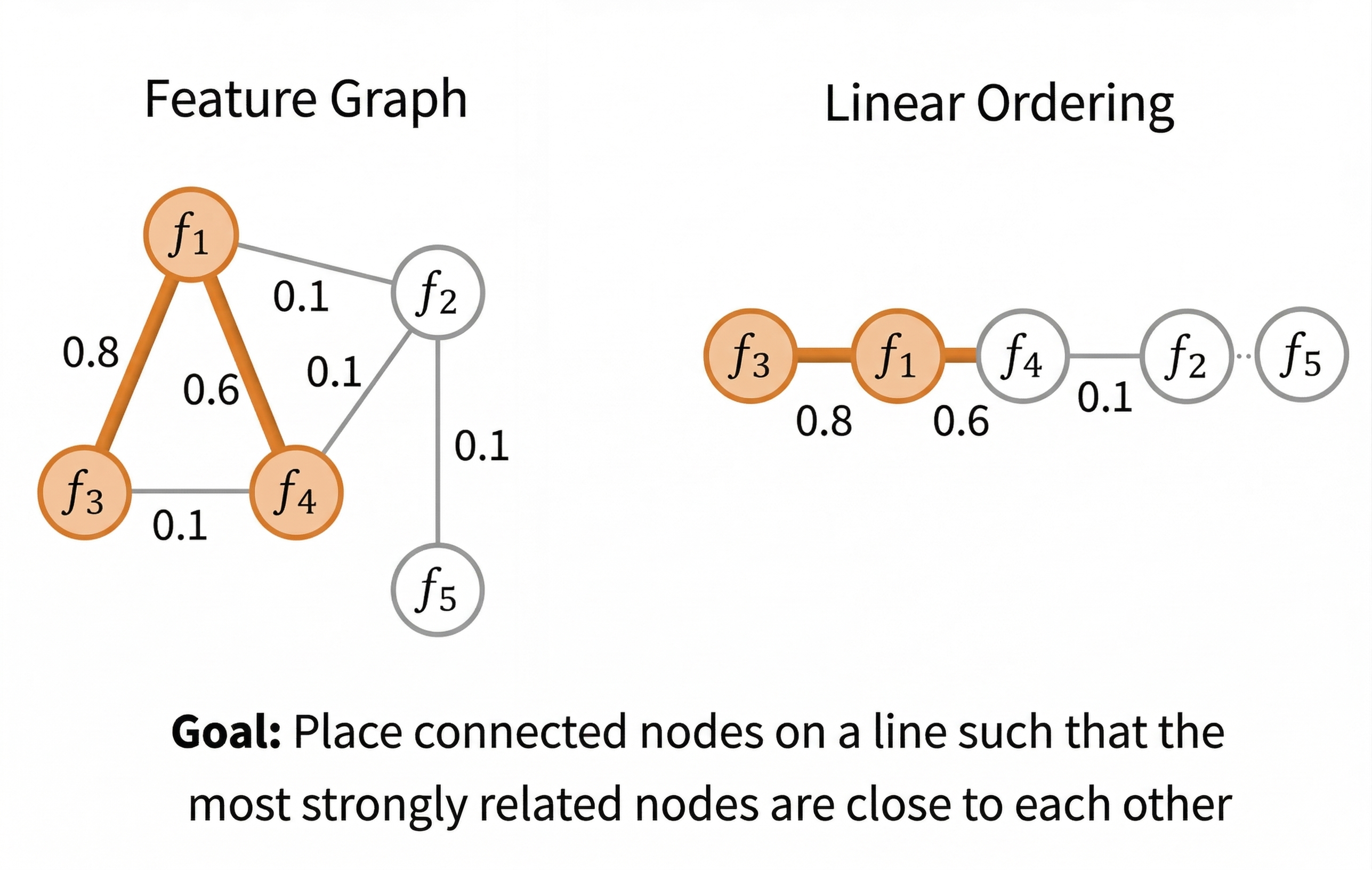
GO-LR animation
Feature graph → linear ordering
Animated graph-to-ordering transformation.
GO-LR treats feature ordering as a graph layout problem. Features are represented as nodes, pairwise feature dissimilarities define weighted edges, and the goal is to produce a linear order where strongly related features remain close in index space.
Ordering cost comparison against classical metaheuristics
On the Colon benchmark, GO-LR was compared against several classical ordering/metaheuristic baselines. Although some baselines achieve lower TSP-style surrogate cost, GO-LR achieves the lowest MinLA-style dispersion cost with the fastest runtime.
| Ordering Method | Runtime | TSP Cost ↓ | MinLA Cost ↓ |
|---|---|---|---|
| GO-LR | 10.07s | \(21958.78\) | \(1.4743\times10^{10}\) |
| Simulated Annealing | 15.01s | \(11712.75\) | \(1.4803\times10^{10}\) |
| Genetic Algorithm | 206.59s | \(11712.75\) | \(1.4803\times10^{10}\) |
| Ant Colony Optimization | 1501.44s | \(11792.08\) | \(1.4760\times10^{10}\) |
| Christofides | 1424.83s | \(11715.06\) | \(1.4994\times10^{10}\) |
Extreme dimensionality: Cell Cycle
On the Cell Cycle RNA-seq dataset with \(n=1067\) samples and \(m=42728\) features, GO-LR achieved a lower MinLA-style dispersion cost than Simulated Annealing, supporting its alignment with the objective used before NSC-pSP compression.
| Ordering Method | MinLA Cost ↓ |
|---|---|
| GO-LR | \(8.14\times10^{11}\) |
| Simulated Annealing | \(8.51\times10^{11}\) |
Interpretation: lower TSP-style surrogate cost alone does not necessarily imply a better ordering for the GOTabPFN pipeline. GO-LR directly targets the MinLA-style dispersion objective used before NSC-pSP compression.
NSC: Neuro-Inspired Subunit Compression
NSC animation
Ordered features → segmentation → PCA pooling → meta-features
Animated illustration of NSC transforming GO-LR ordered features into compact meta-features.
NSC provides the representation interface between GO-LR and frozen TabPFN head. It transforms an ordered high-dimensional feature vector into a compact sequence of meta-features, making TabPFN-style inference more suitable for HDLSS data.
Final Prediction with Frozen TabPFN-2.5
GOTabPFN pipeline summary
GO-LR ordering → NSC compression → pretrained TabPFN-2.5 prediction
Animated summary of GOTabPFN: global feature ordering, structured compression, compact meta-features, and final prediction using a pretrained TabPFN-2.5 checkpoint.
After GO-LR and NSC, each sample is represented by compact meta-features \(Z(x)\). GOTabPFN then applies the pretrained TabPFN-2.5 checkpoint as the final predictor.
Dataset Diagnostics: Feature Ordering - When and Why It Helps
IDF/FOE estimate the opportunity for ordering, while LES measures the realized locality gain over random orderings.
GOTabPFN includes dataset-level diagnostics to estimate whether feature ordering is likely to help. The diagnostics connect when ordering may help with why it helps: useful ordering should expose local neighborhoods that NSC can pool.
| Diagnostic | Interpretation |
|---|---|
| IDF ↓ | Lower intrinsic dimension relative to ambient features; suggests redundancy or compact structure. |
| FOE ↑ | First-pass screening signal for ordering opportunity. |
| LES ↑ | Follow-up diagnostic showing whether GO-LR realizes locality over random ordering. |
| Δ Locality ↑ | Positive AdjCoh, HitRate, and Cut gains indicate improved local neighborhoods over random baselines. |
FOE is used as the first screening barrier for ordering opportunity; LES is a follow-up locality diagnostic that shows whether GO-LR actually realizes useful neighborhoods.
Results
GOTabPFN is evaluated on high-dimensional low-sample-size tabular benchmarks using \(5\times5\) repeated cross-validation. Across the core HDLSS benchmark suite, GOTabPFN achieves the best result on all eight datasets and the lowest average rank.
| Dataset | Best Orig. | GOTabPFN | Abs. Gain | Rel. Gain |
|---|---|---|---|---|
| Colon | 87.85 | 88.18 | +0.33 | +0.38% |
| Lung | 96.55 | 97.44 | +0.89 | +0.92% |
| GLI-85 | 89.66 | 93.82 | +4.16 | +4.64% |
| SMK | 71.99 | 74.23 | +2.24 | +3.11% |
| ALLAML | 97.16 | 97.54 | +0.38 | +0.39% |
| Prostate | 93.31 | 93.37 | +0.06 | +0.06% |
| Arcene | 88.00 | 90.60 | +2.60 | +2.95% |
| TOX | 93.25 | 93.33 | +0.08 | +0.09% |
“Best Orig.” denotes the best original tabular foundation-model head among TabDPT, TabPFN-Wide, BETA, TuneTables, and TabICL. Values are mean accuracies under \(5\times5\) cross-validation.
Comparative Leaderboard
GOTabPFN is compared against strong classical, deep tabular, HDLSS, and tabular foundation-model baselines. The leaderboard summarizes average rank across datasets, where lower rank is better.
Core HDLSS leaderboard
| Rank | Method | Avg. Rank ↓ | Positioning |
|---|---|---|---|
| 1 | GOTabPFN | 1.00 ± 0.00 | Best on all 8 HDLSS datasets |
| 2 | TANDEM | 3.63 ± 1.32 | Strongest non-GOTabPFN average rank |
| 3 | TabPFN-Wide | 3.75 ± 2.38 | Strong TabPFN-style baseline |
| 4 | TabDPT | 4.88 ± 1.69 | Competitive tabular foundation-model baseline |
| 5 | TabICL | 7.63 ± 2.29 | In-context tabular baseline |
| 6 | BETA | 8.13 ± 4.31 | TabPFN Unleashed: another TabPFN variant but computationally slow |
| 7 | TuneTables | 8.38 ± 7.70 | Tuned TabPFN-style baseline |
Cross-domain leaderboard
| Rank | Method | Avg. Rank ↓ | Positioning |
|---|---|---|---|
| 1 | GOTabPFN | 1.25 ± 0.66 | Best average rank; top result on 7/8 tasks |
| 2 | TabPFN-Wide | 3.88 ± 1.62 | Strongest competing average rank |
| 3 | TANDEM | 4.00 ± 1.94 | Competitive on cross-domain tasks |
| 4 | TabDPT | 4.44 ± 1.49 | Strong tabular foundation-model baseline |
| 5 | MLP | 5.25 ± 2.17 | Competitive classical neural baseline |
| 6 | TabICL | 5.31 ± 2.46 | Unsupported/OOM on some tasks |
| 7 | TuneTables | 5.94 ± 1.91 | Useful but less consistent across domains |
Average rank is computed across datasets with lower values indicating better overall performance. OOM or unsupported runs are ranked last in the cross-domain setting.
Conclusion and Project Notes
Conclusion
GOTabPFN makes TabPFN-style small tabular foundation models more effective in HDLSS regimes by coupling MinLA-grounded feature ordering through GO-LR with NSC, a stable locality-preserving compression interface. The resulting order-to-tokenization pipeline converts high-dimensional tables into compact meta-feature sequences for a pretrained TabPFN-2.5 predictor.
Without modifying the TabPFN-2.5 backbone, GOTabPFN improves accuracy and robustness under tight feature budgets, providing a practical route to scalable in-context tabular prediction when \(m \gg n\).
Reproducibility, Impact, and Support
pip install gotabpfn. Reproducing the reported
results requires tabpfn==6.3.1 for TabPFN-2.5 compatibility.
Interactive Demo
Hosted Hugging Face Spaces demos are available so users can upload a tabular dataset and run GOTabPFN without setting up the environment locally. The ZeroGPU version is intended for faster GPU-backed testing, while the CPU backup version is available as an alternative when ZeroGPU is unavailable.
Code and Package
The GOTabPFN repository includes the main GOTabPFN implementation, standalone GO-LR feature ordering, four NSC compression variants, diagnostics scripts, and package test notebooks.
Citation
Al Zadid Sultan Bin Habib, Md Younus Ahamed, Prashnna Kumar Gyawali, Gianfranco Doretto, and Donald A. Adjeroh. GOTabPFN: From Feature Ordering to Compact Tokenization for Tabular Foundation Models on High-Dimensional Data. International Conference on Machine Learning, 2026.
@inproceedings{habib2026gotabpfn,
title = {GOTabPFN: From Feature Ordering to Compact Tokenization for Tabular Foundation Models on High-Dimensional Data},
author = {Habib, Al Zadid Sultan Bin and Ahamed, Md Younus and Gyawali, Prashnna Kumar and Doretto, Gianfranco and Adjeroh, Donald A.},
booktitle = {International Conference on Machine Learning},
year = {2026}
}